Dekompozice programu
Když máme za úkol naprogramovat složitější program, tak se často stává, že člověk je úplně ochrnut velikostí programu a obrovským množstvím neznámého.
V tom nám může pomoct dekompozice problému, což je rozdělení jednoho velkého problému na více menších problémů. Díky dekompozici se nám podaří rozdělit jeden velký problém, který nedokážeme vyřešit, na více menších problémů, které již dokážeme vyřešit.
Dekompozici si můžeme nejdříve demonstrovat na příkladu ze života. Mějme úkol, že chceme uvařit instantní nudle Oyakata příchuť Japanese Classic za 42,90 kč.

Jak bychom postupovali? Uvaření jídla je něco, co totálně nevíme, jak udělat. Můžeme se nad tím ale zamyslet a zkusit tento velký problém rozdělit do více menších činností, které dohromady vytvoří výsledné jídlo.
Tyto činnosti jsou například
- uvařit horkou vodu
- otevřít obal od nudlí
- vytáhnout z obalu omáčku
- zalít nudle horkou vodou
- zadělat nudle s horkou vodou víčkem
- počkat 3 minuty
- vylít vodu
- otevřít víčko
- otevřít obal s omáčkou
- dát omáčku do uvařených nudlí
- promíchat
Nyní jsme si velký problém (uvařit nudle Oyakata) rozdělili na více menších problémů. Co můžeme udělat dál? Již po tomto rozdělení vidíme, že některé činnosti hned víme, jak udělat. Pro uvaření jídla musíme splnit všechny činnosti, ale co můžeme udělat je, že si vybereme tu nejjednodušší čínnost a tu zkusíme udělat izolovaně. Například činnost počkat 3 minuty. Zkusíme udělat to, že počkáme 3 minuty. To zvládli a máme první činnost izolovaně za sebou a víme, jak ji udělat. Pak si vybereme další činnost, co si myslíme, že bychom mohli zvládnout a tu zkusíme udělat.
Takto postupujeme dále se všemi činnostmi, které zvládneme udělat izolovaně. Jednou se však zastavíme, protože už nám bude zbývat udělat jenom činnosti, které zatím nevíme, jak celé udělat. Například bychom chtěli zalít nudle horkou vodou. My ale neumíme vytvořit horkou vodu. Co teď? Rozdělíme si činnost zalití nudlí horkou vodou na dvě menší činnosti. První bude zalití vody libovolnou vodou a druhá bude zalití horkou vodou. Tím opět rozbíjím větší problém na několik menších.
Jakmile umím izolovaně udělat činnosti počkat 3 minuty a zalít nudle vodou, tak nám nezbývá, než tyto dvě činnosti udělat dohromady.
Princip dekompozice je, že se snažíme postupně rozdělovat větší problémy na menší problémy a dělat je izolovaně. Děláme to proto, že udělat nějakou část izolovaně je mnohem jednodušší, než dělat rovnou větší problém. Jakmile zvládneme nějakou část izolovaně, tak další část je začlenit naše izolované řešení do výsledného celku.
Na diagramu si to můžeme zobrazit následovně
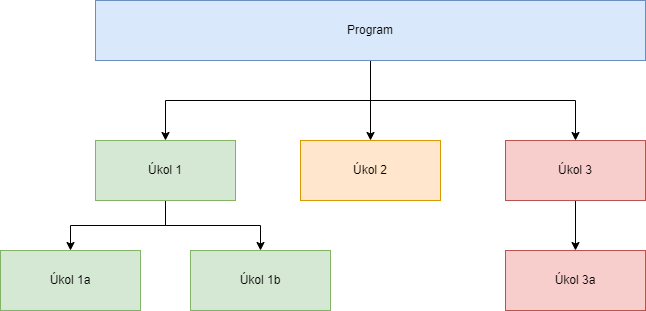
Tímto způsobem bychom se měli dostat k uvařeným nudlím.
Jak to aplikovat v programování
Mějme za úkol naprogramovat program, který přečte ze souboru obsah tohoto souboru a spočítá počet výskytů písmene A. Pokud jich je sudý počet, tak vytiskne dvojnásobný počet písmen A v textu. Pokud jich je lichý počet, tak se načte standardní vstup a spočítá se počet písmen B z tohoto standardního vstupu a vytiskne se jejich počet. Pokud se však v textu nachází dvakrát po sobě mezera, tak se program ukončí a vypíše "Nevalidni vstup". Pokud je první znak libovolného vstupu (ze souboru nebo ze standardního vstupu) písmeno C, tak se navíc vždy vytiskne počet písmen C.
Nyní máme velký program a jak ho začneme řešit? Nejdříve je potřeba se zamyslet, na jaké menší podprogramy bychom program mohli rozdělit. První dvě můžou být například
- Načítání ze souboru
- Počítání písmen A v textu
Zatím třeba chceme řešit druhý problém (počítání písmen A). Ignorujeme tedy to, že se má text načítat ze souboru a udělejme počítání písmen A izolovaně. Program na počítání A může vypadat následovně
#include <stdio.h>
void vytiskni_pocet_a(const char* text_k_analyze) {
int pocet_a = 0;
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
pocet_a = pocet_a + 1;
}
}
printf("Pocet a %i\n", pocet_a);
}
int main() {
char * text = "abfwefcncawfwefg";
vytiskni_pocet_a(text);
return 0;
}
První problém máme tedy vyřešený. Další malá podčást programu je kontrola, kolik počet A máme. Můžeme tedy zatím udělat jen kontrolu izolovaně
#include <stdio.h>
int main() {
int pocet_a = 5;
if (pocet_a % 2 == 0) {
printf("pocet je sudy\n");
} else {
printf("pocet je lichy\n");
}
return 0;
}
Nyní to můžeme dát dohromady (spojit dvě činnosti a udělat je spolu)
#include <stdio.h>
int vrat_pocet_a(const char* text_k_analyze) {
int pocet_a = 0;
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
pocet_a = pocet_a + 1;
}
}
return pocet_a;
}
int main() {
int pocet_a = vrat_pocet_a("abfwefcncawfwefg");
if (pocet_a % 2 == 0) {
printf("pocet je sudy\n");
} else {
printf("pocet je lichy\n");
}
return 0;
}
Nyní chceme vyřešit situaci, kdy jsou v textu dvě mezery. Uděláme si zase malý program, který tento problém řeší izolovaně
#include <stdio.h>
#define CHYBA_DVOJITA_MEZERA -1
int je_chyba_mezer(const char* text_k_analyze) {
char predchozi_znak = '\0';
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == ' ' && predchozi_znak == ' ') {
return CHYBA_DVOJITA_MEZERA;
}
predchozi_znak = text_k_analyze[i];
}
return 0;
}
int main() {
if (je_chyba_mezer("abf wefcn cawfwefg") == CHYBA_DVOJITA_MEZERA) {
printf("dvojita mezera\n");
} else {
printf("vse v poradku\n");
}
return 0;
}
To jsme zvládli a můžeme tento izolovaný program začlenit do velkého programu
#include <stdio.h>
#define CHYBA_DVOJITA_MEZERA -1
int vrat_pocet_a(const char* text_k_analyze) {
char predchozi_znak = '\0';
int pocet_a = 0;
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
pocet_a = pocet_a + 1;
}
if (text_k_analyze[i] == ' ' && predchozi_znak == ' ') {
return CHYBA_DVOJITA_MEZERA;
}
predchozi_znak = text_k_analyze[i];
}
return pocet_a;
}
int main() {
int pocet_a = vrat_pocet_a("abfwefcncawfwefg");
if (pocet_a == CHYBA_DVOJITA_MEZERA) {
printf("Nevalidni vstup\n");
return 1;
}
if (pocet_a % 2 == 0) {
printf("pocet je sudy\n");
} else {
printf("pocet je lichy\n");
}
return 0;
}
Nyní bychom chtěli počítat ještě písmena C. Ale z funkce můžeme vracet jenom jednu hodnotu? Jak to udělat? Můžeme použít strukturu a opět vyřešit tento problém izolovaně
#include <stdio.h>
typedef struct { int pocet_a; int pocet_c; } text_analyza;
text_analyza vrat_analyzu_textu(const char* text_k_analyze) {
text_analyza analyza = { .pocet_a = 0, .pocet_c = 0 };
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
analyza.pocet_a = analyza.pocet_a + 1;
}
if (text_k_analyze[i] == 'c' || text_k_analyze[i] == 'c') {
analyza.pocet_c = analyza.pocet_c + 1;
}
}
return analyza;
}
int main() {
text_analyza analyza = vrat_analyzu_textu("abfwefcncawfwefg");
printf("Pocet a %i\n", analyza.pocet_a);
printf("Pocet c %i\n", analyza.pocet_c);
return 0;
}
Nyní můžeme udělat program, který zjistí, zda je první písmeno C.
#include <stdio.h>
void zjist_prvni_c(const char* text_k_analyze) {
int je_prvni_znak_c = text_k_analyze[0] == 'c';
if (je_prvni_znak_c) {
printf("prvni c\n");
} else {
printf("ne\n");
}
}
int main() {
zjist_prvni_c("cabfwefcncawfwefg");
return 0;
}
Nyní tuto malou část můžeme spojit s předchozí malou částí do většího celku
#include <stdio.h>
typedef struct { int pocet_a; int pocet_c; int prvni_c; } text_analyza;
text_analyza vrat_analyzu_textu(const char* text_k_analyze) {
text_analyza analyza = { .pocet_a = 0, .pocet_c = 0, .prvni_c = 0 };
analyza.prvni_c = text_k_analyze[0] == 'c';
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
analyza.pocet_a = analyza.pocet_a + 1;
}
if (text_k_analyze[i] == 'c' || text_k_analyze[i] == 'c') {
analyza.pocet_c = analyza.pocet_c + 1;
}
}
return analyza;
}
int main() {
text_analyza analyza = vrat_analyzu_textu("cabfwefcncawfwefg");
printf("Pocet a %i\n", analyza.pocet_a);
if (analyza.prvni_c) {
printf("Pocet c %i\n", analyza.pocet_c);
}
return 0;
}
To můžeme doplnit i do kontroly mezer a přidat to do naší struktury.
#include <stdio.h>
#define CHYBA_DVOJITA_MEZERA -1
typedef struct { int pocet_a; int pocet_c; int prvni_c; int chyba_v_mezerach; } text_analyza;
text_analyza vrat_analyzu_textu(const char* text_k_analyze) {
text_analyza analyza = { .pocet_a = 0, .pocet_c = 0, .prvni_c = 0, .chyba_v_mezerach = 0 };
analyza.prvni_c = text_k_analyze[0] == 'c';
char predchozi_znak = '\0';
for(int i = 0; text_k_analyze[i] != '\0'; i = i + 1) {
if (text_k_analyze[i] == 'a' || text_k_analyze[i] == 'A') {
analyza.pocet_a = analyza.pocet_a + 1;
}
if (text_k_analyze[i] == 'c' || text_k_analyze[i] == 'c') {
analyza.pocet_c = analyza.pocet_c + 1;
}
if (text_k_analyze[i] == ' ' && predchozi_znak == ' ') {
analyza.chyba_v_mezerach = CHYBA_DVOJITA_MEZERA;
return analyza;
}
predchozi_znak = text_k_analyze[i];
}
return analyza;
}
int main() {
text_analyza analyza = vrat_analyzu_textu("c abfwefcncawfwefg");
if (analyza.chyba_v_mezerach) {
printf("Nevalidni vstup\n");
return 1;
}
printf("Pocet a %i\n", analyza.pocet_a);
if (analyza.prvni_c) {
printf("Pocet c %i\n", analyza.pocet_c);
}
return 0;
}
Postupně vidíme princip dekompozice. Vybereme si malý problém. Ten se pokusíme naimplementovat v co nejjednodušším programu. Jakmile to zvládneme, tak ten malý podprogram doplníme do většího a postupujeme dál.
Tímto způsobem jste schopni dělat velmi složité programy.
Celý program tady dokončovat nebudeme. Můžete si ho dokončit za domácí úkol.